
Reading Time: 10 minutes
Ansible Playbook, written in YAML language, serves as a powerful tool for task automation. This guide navigates you through the essentials of crafting Ansible Playbooks, containing sets of instructions executed on destination hosts. Dive into the basics, syntax, and practical execution, enhancing your proficiency in infrastructure management.
What is Ansible
This tutorial will guide you on How to create an Ansible Playbook. Ansible is Open source command line tool that can be used in IT automation software. Ansible is written in Python.
Ansible is simple to use and its main focus is on security. It uses OpenSSH for transport. Users can use Ansible without a lot of training however basic training is required.
Table of Contents
What is Ansible Playbook
Ansible Playbook is a set of instructions that can help us to achieve our goals. general syntax. Ansible Playbooks are files written in YAML language. It contains a single or more set of tasks that can be executed on the destination hosts. Ansible Playbooks require more care due to their syntax.
This tutorial will guide you through the basics of writing Ansible Playbooks and executing commands on destination systems.
If you have not installed ansible on your System, Please follow the tutorial on how to install ansible on Ubuntu. We assume you are using Ubuntu System as the master node however you can still follow this tutorial for Redhat or any other system. You can install ansible on Redhat, and Centos using $ sudo yum install ansible
- Ansible Playbooks are YAML files containing instructions for task automation.
- Follow syntax carefully when crafting Playbooks for streamlined execution.
- Pre-requisites include an Ansible Master Node (Ubuntu/Debian) and a remote Ansible Client Machine (e.g., Debian Server).
- Create a custom Ansible Inventory to manage remote hosts effectively.
- Groups in the inventory, like [Allhosts], [webserver], [QAhosts], and [Prodhosts], help organize hosts based on their roles or environments.
Pre-requisites
To get the maximum value out of this guide, we suggest following along. The below are things you require in order to learn How to create an Ansible Playbook
- Ubuntu or Debian- This is the machine we use to connect to the remote machines using SSH. This is also called Ansible Master Node
- A remote machine to control with Ansible – We recommend getting a Linux system such as Debian Server. This is called an ansible client Machine.
Once you have both of the above requirements met, we can start.
If you have not configured Ansible Inventory, Please create one. You can follow the tutorial “How to setup Ansible Inventory” or use the below instructions for setting up Inventory in order to learn How to create an Ansible Playbook
You can manage remote hosts using Ansible & you need to inform Ansible that this is your Inventory. You can achieve this by creating an inventory file that will contain hostnames (FQDN) or IP addresses of servers/ Devices.
By default, the host inventory file is in/etc/ansible/hosts however some users may not have access to /etc directory hence we will use custom inventory and you can create the same in your home directory or any location you prefer.
Edit the myinventory file and add the IP address of your remote machine as shown below:

You can see [Allhosts] , [webserver] , [QAhosts], [Prodhosts]
These are called groups under inventory, You can either mention the IP address of hosts or FQDN
[Allhosts] – You can mention all host IPs/Names.
[webserver] – You can mention all of your web hosts
[QAhosts] – This can have only QA or nonprod hosts
How to Write an Ansible Playbook
As said earlier, You need to strictly follow syntactical while writing Ansible playbooks
If you are not familiar with how to write YAML files, We will have another tutorial however for now follow below syntax and instructions.
Now, let us create a directory where we are going to keep all our playbooks.
$ mkdir myplaybooks
cd myplaybooks/vim test.yaml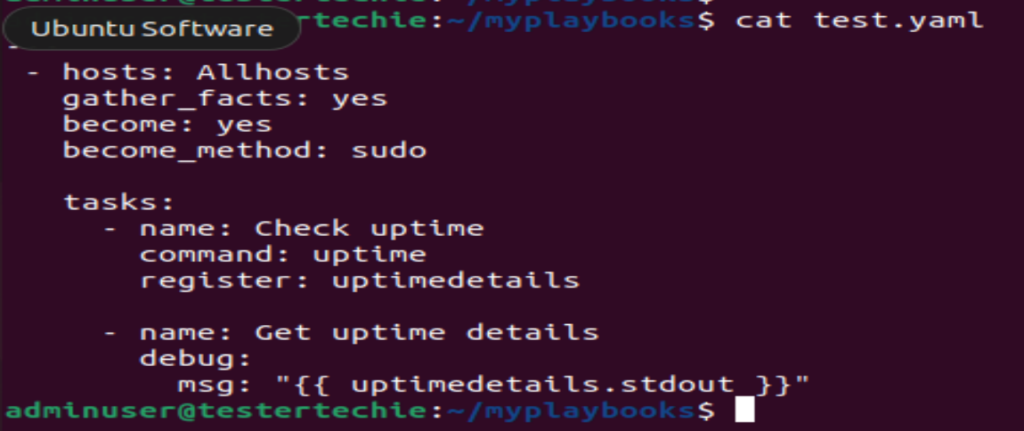
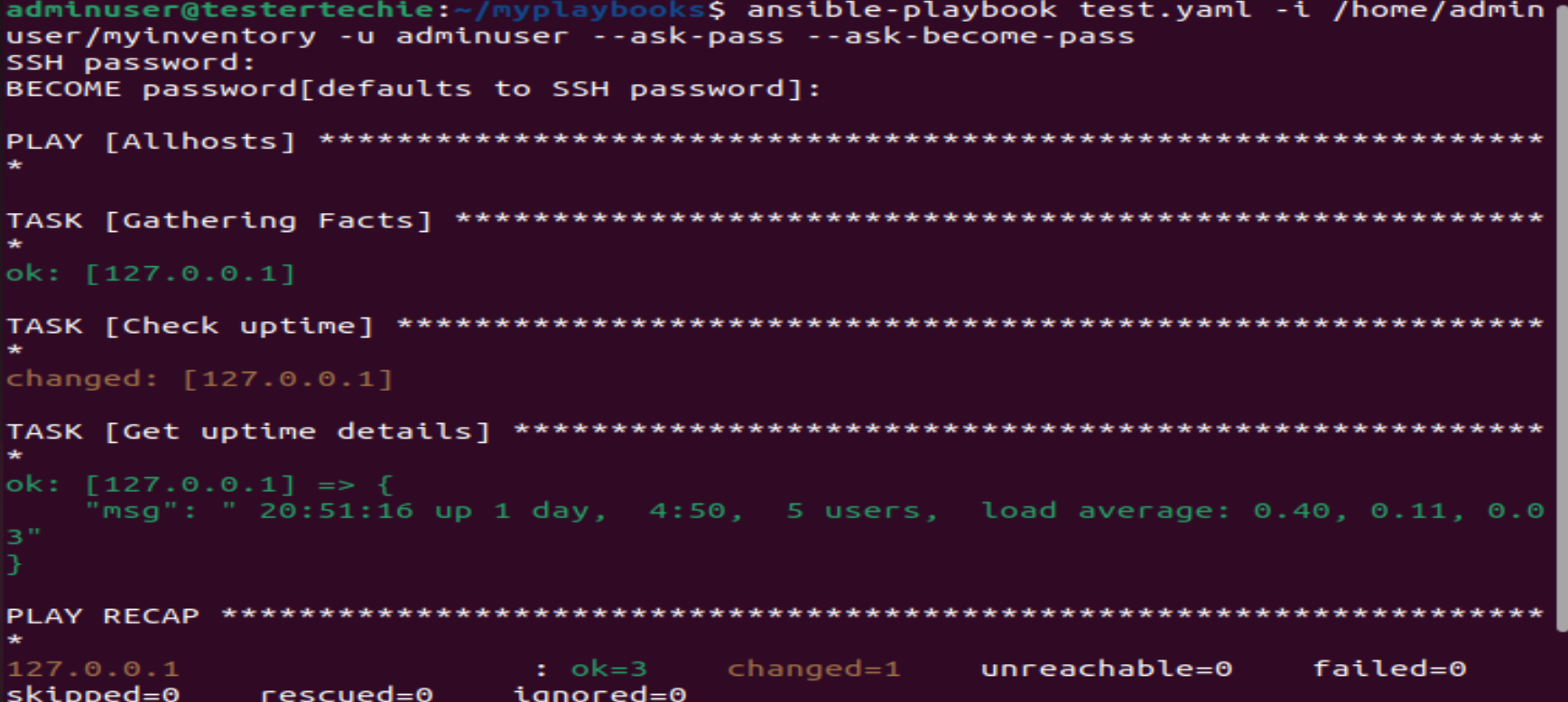
$ ansible-playbook test.yaml -i /home/adminuser/myinventory -u adminuser --ask-pass --ask-become-pass- -i = This is a custom inventory path
- -u = This is username that you will use to access remote hosts
- –ask-pass = This will prompt you to enter ssh password
- –ask-become-pass = This is used for sudo password.
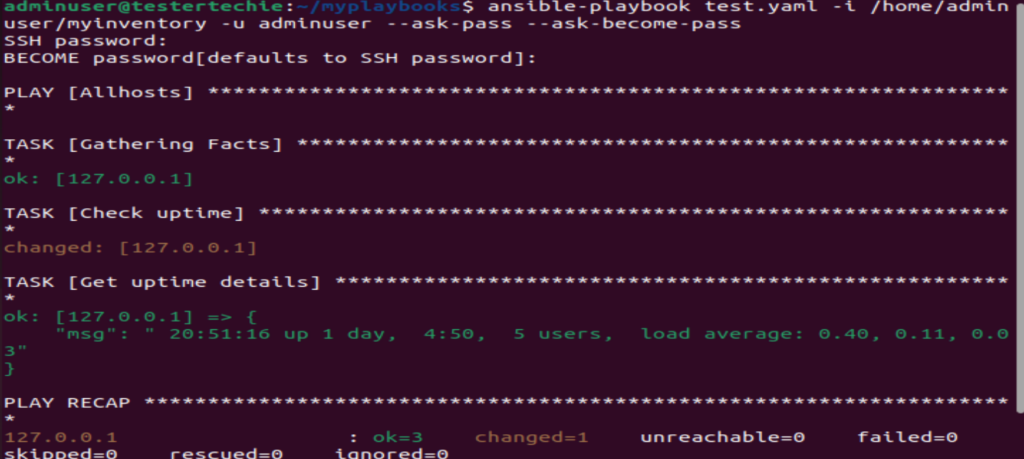
We are running the command “uptime” and registering the output of uptime in debug & printing the output using a msg, This is a great way to register output. You can write many more playbooks to achieve your tasks.
What role does Ansible Galaxy play in sharing and reusing Ansible content?
Ansible Galaxy plays a crucial role in sharing and reusing Ansible content by serving as a centralized hub for sharing roles, collections, and other Ansible artifacts. Here are key aspects of Ansible Galaxy:
- Role Distribution and Discovery: Ansible Galaxy is a platform where Ansible roles are distributed and discovered. Users can publish their roles to Galaxy, making them accessible to the broader Ansible community.
- Central Repository: Galaxy serves as a central repository for Ansible content, allowing users to easily find, download, and use roles and collections developed by others. It eliminates the need to search for roles across different sources.
- Structured Organization: Ansible content on Galaxy is organized into roles and collections, providing a clear and structured way to package and share Ansible automation content.
- Metadata and Documentation: Galaxy provides a platform for role authors to include metadata and documentation with their roles. This includes information about role dependencies, supported platforms, version history, and usage instructions.
- Versioning and Releases: Roles and collections in Galaxy are versioned, allowing users to specify the desired version when including a role in their playbooks. This versioning system ensures consistency and helps manage changes over time.
- Search and Filters: Galaxy offers search functionality and filters, making it easy for users to discover roles based on keywords, categories, and other criteria. This simplifies the process of finding relevant Ansible content.
- Dependencies Management: Ansible Galaxy allows role authors to define dependencies, enabling users to easily install required roles along with the roles they directly include in their playbooks.
- Integration with Ansible CLI: Ansible Galaxy seamlessly integrates with the Ansible command-line interface (CLI). Users can use the
ansible-galaxycommand to install roles directly from Galaxy, making the process of incorporating external roles into playbooks straightforward.Example command:bashCopy codeansible-galaxy install username.role - Quality and Rating System: Galaxy includes a quality and rating system that allows users to provide feedback and ratings for roles. This helps the community identify well-maintained and reliable roles.
- Role Tags and Topics: Roles in Galaxy can be tagged with keywords and topics, making it easier to categorize and find roles related to specific technologies, applications, or use cases.
By serving as a collaborative platform for sharing, discovering, and reusing Ansible automation content, Galaxy fosters community collaboration, accelerates development, and promotes best practices in Ansible role creation and management.
How does Ansible address the challenges of managing diverse operating systems?
Ansible addresses the challenges of managing diverse operating systems by providing a flexible and platform-agnostic automation framework. Here are several ways Ansible handles the diversity of operating systems:
- Agentless Architecture: Ansible operates in an agentless manner, meaning that it does not require any agent or additional software to be installed on managed hosts. This architecture allows Ansible to work seamlessly across a wide range of operating systems without imposing specific dependencies.
- Module Abstraction: Ansible abstracts system operations into modules, which are units of work that can be executed on a target system. These modules are designed to be platform-independent, and Ansible automatically selects the appropriate module based on the target operating system.
- Task Conditionals: Ansible playbooks can include conditional statements based on facts about the target systems, such as the operating system type or version. This allows users to execute tasks conditionally depending on the specific characteristics of each host.Example conditional in a playbook:yamlCopy code
- name: Install package based on OS package: name: "{{ item }}" state: present loop: - httpd - nginx when: "ansible_facts['os_family'] == 'RedHat'" - Dynamic Inventories: Ansible supports dynamic inventories, allowing users to automatically discover and manage hosts based on various criteria, including operating system type and version.
- Variable Handling: Ansible enables the use of variables, allowing users to define platform-specific configurations. Variables can be set based on facts gathered during playbook execution, ensuring that roles and tasks adapt to the characteristics of each system.Example variable usage in a playbook:yamlCopy code
- name: Configure web server based on OS include_role: name: "{{ item }}" loop: - web_server/apache - web_server/nginx vars: apache_packages: - httpd nginx_packages: - nginx when: "'RedHat' in ansible_facts['os_family']" - Platform-Specific Modules: Ansible includes platform-specific modules that allow users to interact with operating system features or configurations that are unique to certain platforms. For example,
yumfor Red Hat-based systems andaptfor Debian-based systems. - Common Language: Ansible playbooks are written in YAML, providing a common language for automation. This consistency allows users to express automation tasks in a standardized way regardless of the underlying operating system.
- Community Contributions: The Ansible community actively contributes to the development and maintenance of modules, roles, and playbooks that support a wide array of operating systems. This collaborative effort ensures that Ansible remains adaptable to new releases and diverse environments.
By incorporating these features, Ansible offers a powerful and versatile solution for managing diverse operating systems, providing a unified approach to automation that spans across different platforms and distributions.
What strategies does Ansible provide for handling configuration drift in infrastructure?
Ansible provides several strategies for handling configuration drift in infrastructure, ensuring that the actual state of systems aligns with the desired state specified in playbooks. Here are key strategies:
- Idempotent Tasks: Ansible tasks are designed to be idempotent, meaning they can be run multiple times without changing the result after the first run. This inherent idempotency ensures that running playbooks regularly helps correct any configuration drift.
- Regular Execution of Playbooks: Schedule the execution of Ansible playbooks at regular intervals to continuously enforce the desired state. Regular execution helps identify and rectify configuration drift promptly.
- Dynamic Inventories: Use dynamic inventories to automatically discover and update information about hosts. This is especially useful in dynamic environments where hosts may be added or removed frequently, helping to maintain an up-to-date inventory.
- Periodic Audits: Implement tasks within playbooks that perform configuration audits. These tasks can check the actual state against the desired state and report any discrepancies. Regular audits are essential for detecting and addressing drift.
- Monitoring and Alerting: Set up monitoring and alerting mechanisms to notify administrators when configuration drift is detected. Integrating Ansible with monitoring tools allows for proactive identification of issues.
- Custom Scripts for Drift Detection: Create custom scripts or tasks within Ansible playbooks to detect specific configuration drift scenarios. These scripts can check for inconsistencies and report back on areas where drift is occurring.
- Configuration Management Databases (CMDBs): Integrate Ansible with CMDBs or external systems that store configuration information. Regularly synchronize Ansible with these databases to ensure accurate and up-to-date information.
- Version-Controlled Playbooks and Roles: Use version control systems like Git to track changes in playbooks and roles. This enables a historical view of configurations and facilitates rollback in case of unexpected drift.
- Configuration Baselines: Establish configuration baselines for different environments (e.g., development, testing, production). Regularly compare the current configuration against these baselines to identify and correct drift.
- Automated Remediation: Implement automated remediation tasks within playbooks. When configuration drift is detected, Ansible can automatically apply the necessary changes to bring the system back to the desired state.
- Documentation and Comments: Ensure that playbooks and roles include detailed documentation and comments explaining the intended configuration. This makes it easier to understand the desired state and identify areas where drift might occur.
By combining these strategies, Ansible provides a comprehensive approach to handling configuration drift in infrastructure. This proactive and automated approach ensures that systems remain in compliance with the specified configurations, minimizing the risk of security vulnerabilities and operational issues.
How can Ansible be integrated with version control systems for optimal workflow?
Integrating Ansible with version control systems (VCS) is essential for establishing an optimal workflow, enabling collaboration, version tracking, and automation. Here are steps to integrate Ansible with version control systems, focusing on Git as an example:
1. Set Up a Git Repository:
- Create a Git repository to store your Ansible playbooks, roles, and related files.
2. Version Control Playbooks and Roles:
- Commit your playbooks, roles, and related files to the Git repository. Use meaningful commit messages to describe changes.
bashCopy code
git add . git commit -m "Initial commit: Adding Ansible playbooks and roles"
3. Create Git Branches:
- Use branches to separate development, testing, and production environments. This facilitates parallel development and testing without affecting the main production branch.
bashCopy code
git branch development git checkout development
4. Utilize Tags for Releases:
- Use Git tags to mark releases or specific versions of your Ansible playbooks. This helps in tracking changes and facilitates rollback if needed.
bashCopy code
git tag -a v1.0 -m "Release version 1.0"
5. Collaborative Work with Pull Requests:
- If multiple team members are working on Ansible content, use pull requests or merge requests (depending on your VCS) to review and integrate changes. This ensures code quality and facilitates collaboration.
6. Continuous Integration (CI) Integration:
- Integrate Ansible with CI tools (e.g., Jenkins, GitLab CI, GitHub Actions) to automate testing and deployment processes. CI helps catch issues early and ensures that changes adhere to best practices.
7. Automate Testing:
- Set up automated testing for your Ansible playbooks and roles. Use tools like Molecule to perform tests on different platforms and configurations. Incorporate testing into your CI/CD pipeline.
8. CI/CD Deployment Pipelines:
- Create CI/CD pipelines that trigger Ansible playbooks based on events such as code commits or releases. This ensures a seamless and automated deployment process.
9. Secrets Management:
- Use a secrets management solution to handle sensitive information (e.g., passwords, API keys). Avoid storing secrets directly in playbooks or roles. Tools like Ansible Vault or external solutions can be integrated into your workflow.
10. Documentation as Code:
- Include documentation as code within your Git repository. This can include README files, inline comments in playbooks, and documentation within roles. Keep documentation up-to-date with changes.
11. Branch Protection Rules:
- Implement branch protection rules in your Git repository to control who can merge changes into critical branches (e.g., master). This adds an extra layer of control to prevent accidental or unauthorized changes.
12. Rollback Plan:
- Always have a rollback plan in case issues arise during deployment. Use Git tags or branches to easily revert to a previous known-good state.
13. Security Audits and Compliance:
- Integrate security scanning tools into your CI/CD pipeline to perform security audits. Ensure that your Ansible content complies with security policies and best practices.
By following these steps, you can establish a robust workflow that integrates Ansible seamlessly with version control systems. This approach enhances collaboration, version tracking, and automation, ensuring a streamlined and efficient development and deployment process.
Conclusion
As you know the functionality of developing playbooks entirely depends on the tasks you will perform however I hope these instructions help you with basic guidelines and instructions to develop playbooks and implement How to create an Ansible Playbook and use this
You can follow the tutorial “How to use Ansible“
I have written a Tutorial “How to install Ansible“, Please go through it.
You can find all Ansible tutorials on this page.
You can find Jenkins Tutorials on this page
You can also find all Video Tutorial on Youtube
Do you have any further questions on How to create an Ansible Playbook, Please write to us so we can try to assist on How to create an Ansible Playbook and use it?
Official Ansible website
Follow us on Facebook Twitter X Reddit Quora Linkedin Tubmblr Youtube